Extract Data from PDF Documents with PDFScrape
The fastest and most accurate way to extract and analyze data from PDF files, including scanned documents and images.
10,000+
PDFs Processed
99.7%
Accuracy Rate
5,000+
Happy Users
24/7
Support
Powerful PDF Text Extraction
Extract Data from Any PDF
Easily extract data from all types of PDF files, including scanned documents, images, and native PDFs. No technical skills required.
AI-Powered Extraction
Our advanced AI technology accurately recognizes and extracts text from PDFs, even from complex layouts and low-quality scans.
Structured Data Output
Create custom scrapers to extract specific information and convert unstructured PDF content into structured, analyzable data.
Get started instantly with PDFScrape
No credit card required. Free plan includes up to 50 pages per month.
It's All About the Schema
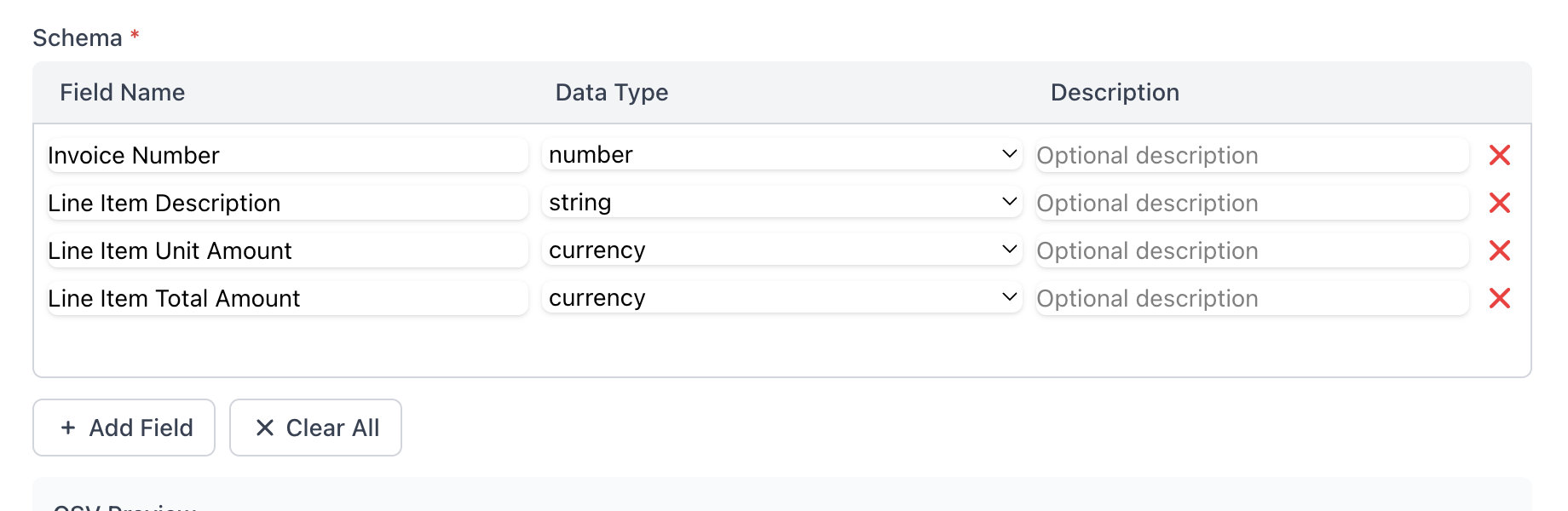
PDFScrape lets you define your own custom schema - a set of headers and descriptions for your CSV output that tells our AI exactly what data to parse from your documents.
Simply describe what you want to extract, and our intelligent system will scrape that specific information from any PDF. No coding required.
Whether you need to extract invoice details, gather research data, or pull information from forms, our schema-based approach makes PDF data extraction faster and more accurate than ever.
How to Extract Data from a PDF
Upload Your PDF
Upload any PDF file you need to extract text from - including scanned documents and images.
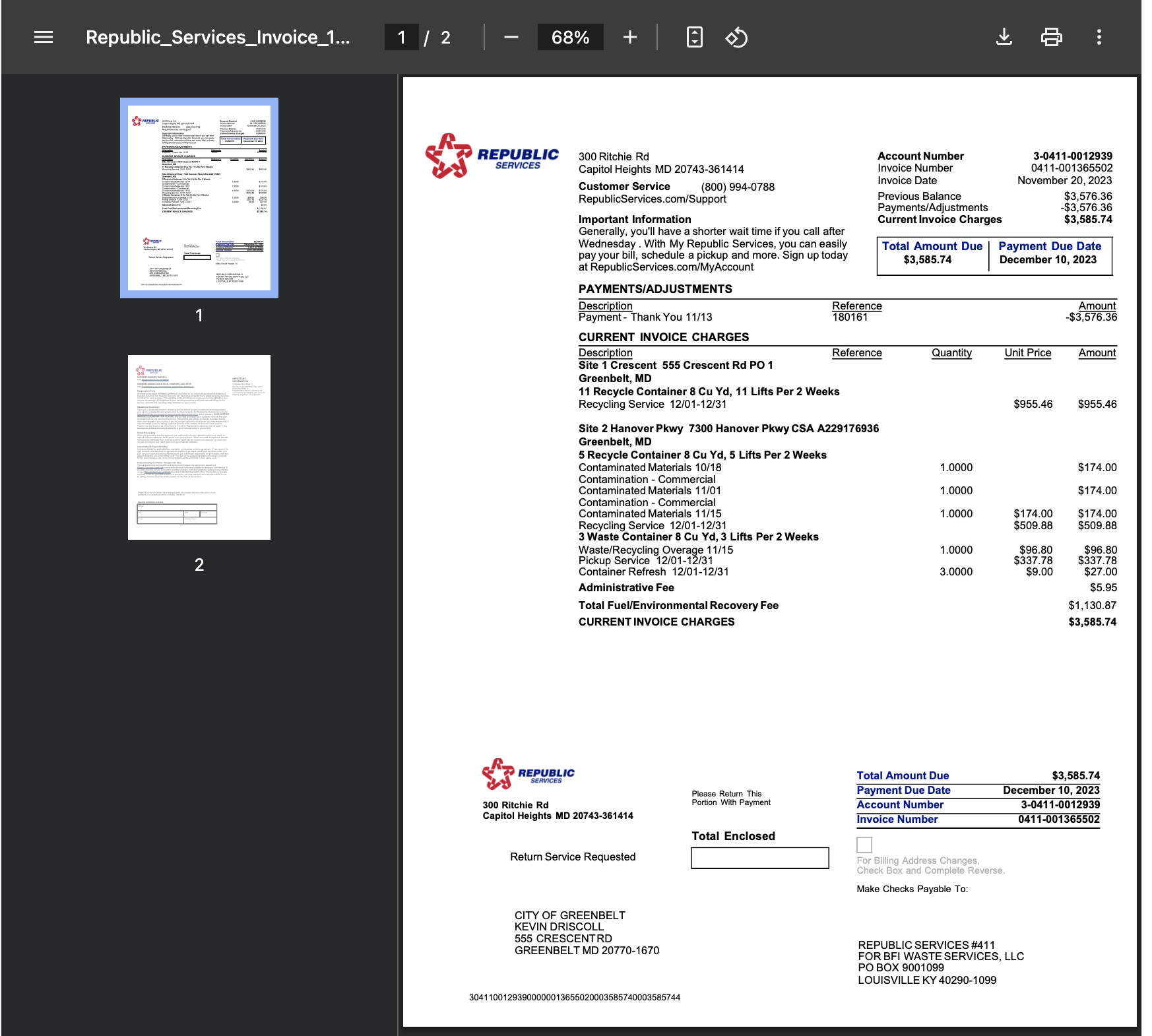
Create a Scraper
Define what information you want to extract from your PDF documents.
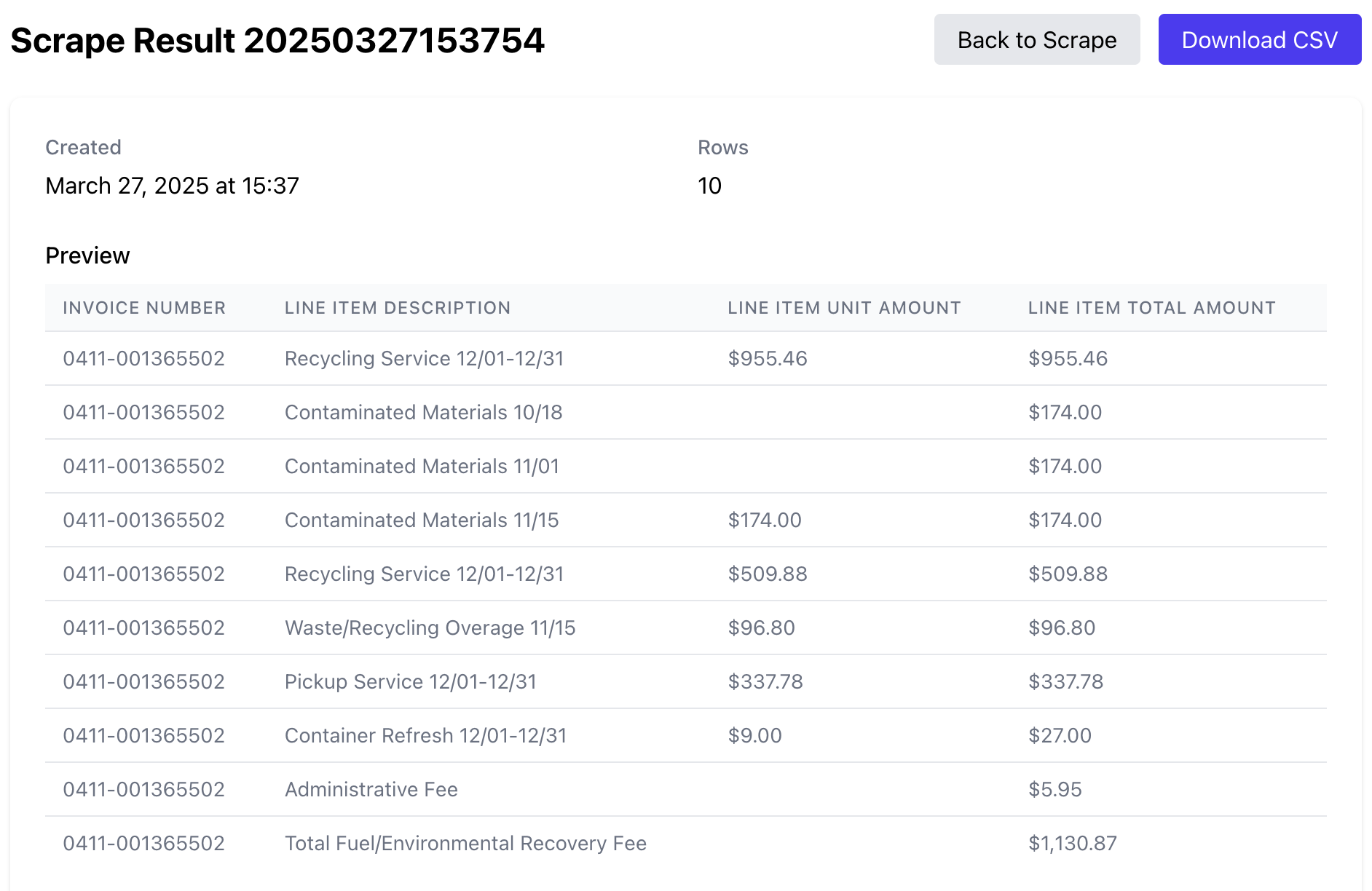
Get Structured Results
PDFScrape processes your documents and delivers the extracted text in a usable format.
Transform Your Document Workflow
Join thousands of professionals who save hours every week by automating their PDF data extraction. Get started free today and see results in minutes.
Frequently Asked Questions
How do I extract data from a PDF file?
With PDFScrape, you simply upload your PDF, create a scraper defining what data you need, and let our AI do the work. No programming or technical skills needed.
Can I extract data from PDF images or scans?
Yes! PDFScrape can extract data from scanned documents and images embedded in PDFs using advanced OCR and AI technology.
Do I need Python to extract data from PDFs?
No programming required. While many solutions require Python coding, PDFScrape provides a user-friendly interface that handles all the technical aspects for you.
How accurate is the data extraction?
PDFScrape achieves industry-leading accuracy using advanced AI models specifically trained for document understanding. Our system continuously improves with each document processed.
Is my data secure and private?
Absolutely. PDFScrape is committed to industry-leading data protection practices. We never use your documents to train our models, and you maintain full control over your data and how long it's retained.
Ready to Extract Data from Your PDFs?
Join thousands of users who save time and effort by using PDFScrape to extract and analyze data from PDF documents.
Get Started FreeNo credit card required. Start extracting text in minutes.