Getting Started with PDFScrape: Core Concepts
1. Documents
Your uploaded PDF files that contain the data you want to extract.
2. Scrapers
Definitions that specify what data to extract and how to structure it.
3. Runs
The process of applying a Scraper to one or more Documents to extract data.
Quick Start
PDFScrape works through three core components: Documents (your uploaded PDFs), Scrapers (definitions of what data to extract), and Runs (the process of applying a Scraper to one or more Documents). Upload your PDFs, create a Scraper by defining the data structure you want, then run the Scraper against your Documents to extract structured data as CSV or Excel files.
Welcome to PDFScrape! This guide will walk you through the three fundamental components that make up the PDFScrape workflow. Understanding these core concepts will help you quickly start extracting valuable data from your PDF documents.
PDFScrape was designed to make PDF data extraction intuitive and accessible for everyone. Whether you're a data analyst, researcher, or business professional, our platform simplifies the process of transforming unstructured PDF data into structured, usable formats.
The Three Core Components of PDFScrape
PDFScrape's workflow revolves around three primary components that work together to transform your PDFs into structured data:
1. Documents
Your uploaded PDF files that contain the data you want to extract.
- Upload single or multiple PDFs
- Process reports, forms, statements
- Manage document organization
- Text extraction and preparation
2. Scrapers
Definitions that specify what data to extract and how to structure it.
- Define schemas (column headers)
- Create reusable templates
- Set data types and formats
- Configure extraction rules
3. Runs
The process of applying a Scraper to one or more Documents to extract data.
- Execute data extraction
- Monitor processing status
- Review extraction results
- Download structured data
These three components form a simple yet powerful workflow that takes your PDFs from unstructured documents to organized, actionable data. Let's explore each component in detail.
Get started instantly with PDFScrape
No credit card required. Free plan includes up to 50 pages per month.
Component 1: Documents
Documents are the starting point of your PDFScrape journey. These are the PDF files that contain the data you want to extract.
Uploading Documents
PDFScrape makes it easy to get your documents into the system:
- From your dashboard, click the "Upload Document" button
- Select one or more PDF files from your computer
- Alternatively, drag and drop files directly onto the upload area
- Once uploaded, your documents will appear in your document library
Supported Document Types:
- Native PDFs - PDFs with selectable text
- Scanned PDFs - Image-based PDFs (automatically processed with OCR)
- Form PDFs - Documents with form fields and structured data
- Password-protected PDFs - Secure documents (you'll be prompted for the password)
Document Processing
After uploading, PDFScrape automatically processes your documents to prepare them for data extraction:
- Text Extraction - PDFScrape reads all text from the document
- OCR Processing - For scanned documents, optical character recognition converts images to text
- Chunking - The document is divided into manageable sections for efficient processing
- Indexing - Text is indexed for faster searching and extraction
This processing step is crucial as it transforms your raw PDF into a format that's optimized for AI-powered data extraction.
Pro Tip: Document Organization
For optimal results, consider organizing similar documents together. PDFScrape learns from patterns in your documents, so grouping invoices, financial statements, or reports of the same type can improve extraction accuracy.
Component 2: Scrapers
Scrapers are the blueprints that tell PDFScrape exactly what data to extract from your documents and how to structure it. Think of a Scraper as the definition of your output format—what columns you want in your final spreadsheet.
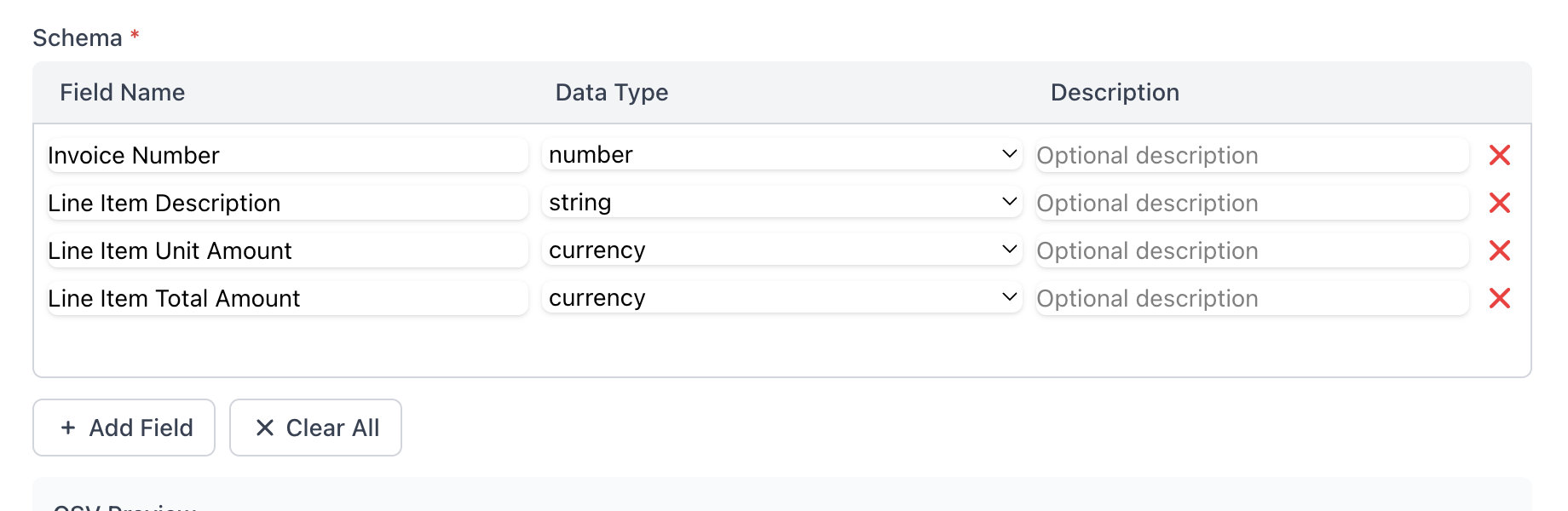 PDFScrape's Schema Editor Interface
PDFScrape's Schema Editor Interface
Creating a Scraper
To create a new Scraper:
- Navigate to the "Scrapers" section in your dashboard
- Click "Create New Scraper"
- Give your Scraper a descriptive name (e.g., "Invoice Extractor" or "Financial Statement Parser")
- Define your schema using the Schema Editor
Understanding Schemas
The schema is the heart of your Scraper. It defines the structure of your output data, similar to columns in a spreadsheet:
Schema Components:
Column Headers
Define the names of columns in your output (e.g., "Invoice Number", "Date", "Amount").
Data Types
Specify the type of data in each column (text, number, date, currency, etc.).
Extraction Rules
Optional rules to help identify specific data (e.g., "follows the text 'Invoice #:'").
Formatting Options
Define how the extracted data should be formatted (date formats, decimal places, etc.).
For example, if you're extracting data from invoices, your schema might include columns for Invoice Number, Date, Customer Name, Item Description, Quantity, Price, and Total.
Schema Examples
Here are some common schema setups for different document types:
| Document Type | Example Schema Columns |
|---|---|
| Invoice | Invoice Number, Date, Customer, Item, Quantity, Unit Price, Total |
| Financial Statement | Period, Revenue, Expenses, Net Income, Assets, Liabilities, Equity |
| Research Paper | Author, Title, Publication Date, Methodology, Sample Size, Results, Conclusion |
| Medical Record | Patient ID, Visit Date, Diagnosis, Treatment, Medication, Dosage, Notes |
Pro Tip: Reusable Scrapers
Create Scrapers for document types you frequently process. Once defined, you can reuse a Scraper on any new documents of the same type, saving significant setup time for recurring extraction tasks.
Ready to extract data from your PDFs?
PDFScrape makes it easy to convert unstructured PDF data into usable formats. Create your free account today and start processing your first document in less than 5 minutes.
Component 3: Runs
A Run (sometimes called a "Scrape") is the process of applying a Scraper to one or more Documents to extract the defined data. This is where the actual data extraction happens.
Creating a Run
To start a data extraction Run:
- Navigate to the "Runs" section in your dashboard
- Click "Create New Run"
- Select the Scraper you want to use
- Choose one or more Documents to process
- Click "Start Run" to begin the extraction
Run Processing
Once initiated, a Run goes through several phases:
Initialization
The system prepares the documents and schema for processing
Scraping
AI analyzes document chunks to identify and extract target data
Post-Processing
System validates and refines the extracted data
Completion
Extracted data is compiled and made available for download
Run Results
After a Run completes, you'll be able to:
- Preview the extracted data in a table format
- Validate the accuracy of the extraction
- Download the data in various formats (CSV, Excel, JSON)
- View processing statistics like confidence scores and extraction time
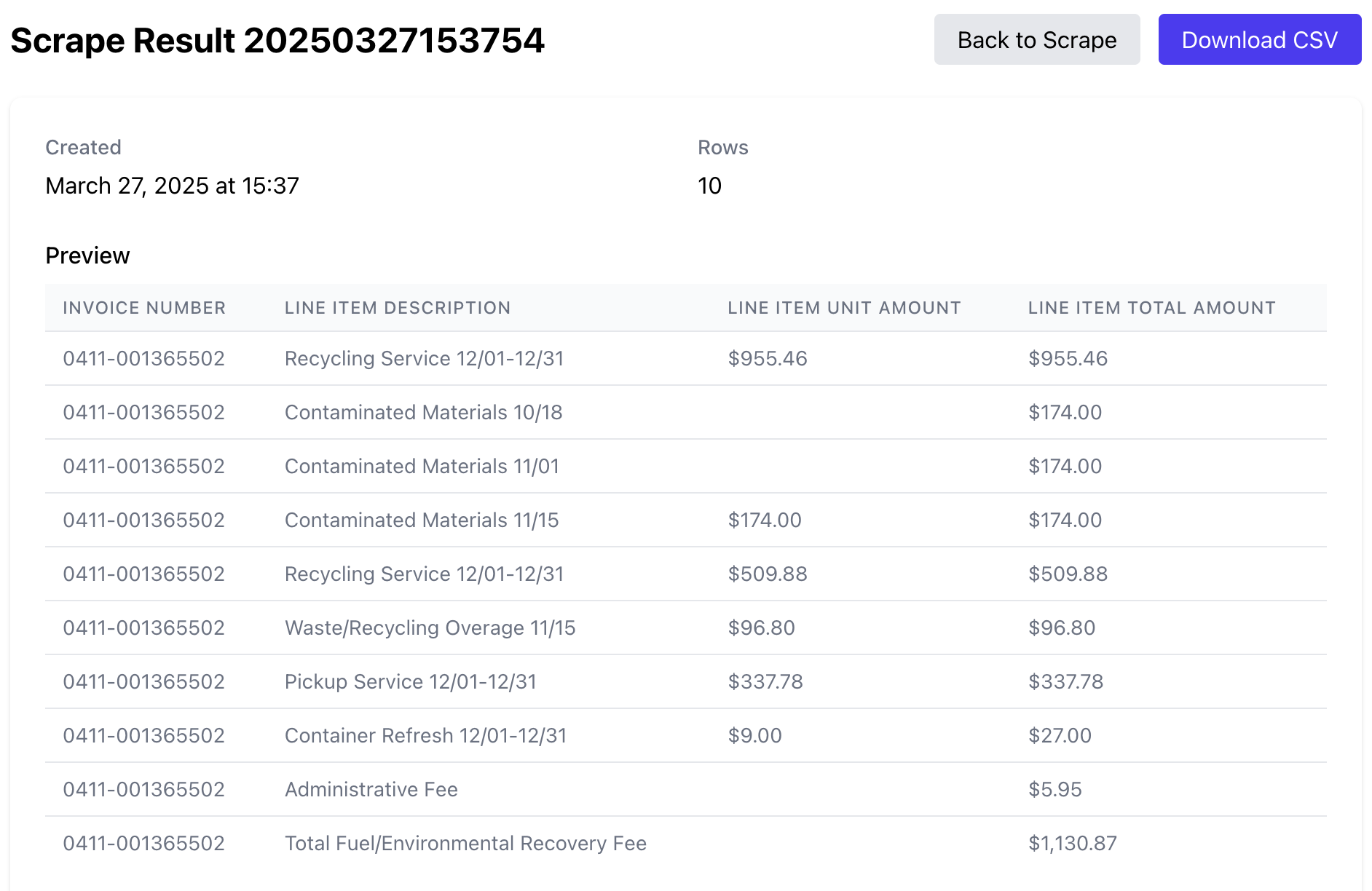 Run Results and Data Preview
Run Results and Data Preview
Managing Runs
PDFScrape keeps a history of all your Runs, allowing you to:
- Track processing status of ongoing extractions
- Review past extractions and their results
- Reuse successful Runs as templates for new extractions
- Compare extraction results across different Scrapers or document sets
Pro Tip: Batch Processing
For large document sets, you can include multiple Documents in a single Run. PDFScrape will process them in parallel, saving significant time compared to processing them individually.
Putting It All Together: The Complete PDFScrape Workflow
Now that you understand the three core components, let's see how they work together in a typical workflow:
-
Upload Your Documents
Start by uploading the PDF documents containing the data you need to extract.
The system automatically processes and prepares these documents for extraction.
-
Create or Select a Scraper
Define your extraction schema—what data you want to pull from the documents and how it should be structured.
You can create a new Scraper or use one you've previously defined.
-
Start a Run
Apply your Scraper to your Documents to begin the extraction process.
PDFScrape's AI will analyze your documents and extract the specified data.
-
Download Your Structured Data
Once processing is complete, preview and download your data in CSV, Excel, or other formats.
Your unstructured PDF data is now transformed into structured, actionable information.
This workflow can be repeated for different documents or data extraction needs, using existing Scrapers or creating new ones as required.
Common Use Cases
Financial Document Processing
Extract data from invoices, financial statements, and expense reports.
Example Workflow:
- Upload monthly financial statements
- Create a Scraper for income, expenses, and balances
- Run the Scraper against all statements
- Export to Excel for financial analysis
Research Data Collection
Extract structured data from research papers, studies, and reports.
Example Workflow:
- Upload collection of research papers
- Create a Scraper for methodology, sample size, and results
- Process all papers in a single Run
- Export to CSV for meta-analysis
Contract Analysis
Extract key terms, dates, and clauses from legal contracts.
Example Workflow:
- Upload vendor contracts
- Create a Scraper for parties, effective dates, and termination clauses
- Run the extraction process
- Export to CSV for contract management system
Healthcare Record Processing
Extract patient data, diagnoses, and treatment information from medical records.
Example Workflow:
- Upload anonymized patient records
- Create a Scraper for diagnoses, treatments, and outcomes
- Process records in batches
- Export to structured database for analysis
Next Steps
Now that you understand the core components of PDFScrape, you're ready to start extracting valuable data from your PDF documents:
- Explore our sample Scrapers to see how different extraction scenarios are configured
- Upload a test document to familiarize yourself with the document processing workflow
- Create your first Scraper tailored to your specific data extraction needs
- Run your first extraction and see how PDFScrape transforms your unstructured data
Remember, PDFScrape is designed to get more intelligent over time. The more you use it, the better it becomes at understanding and extracting data from your specific document types.
Transform Your Document Workflow
Join thousands of professionals who save hours every week by automating their PDF data extraction. Get started free today and see results in minutes.