How to Extract Data from PDF to Excel
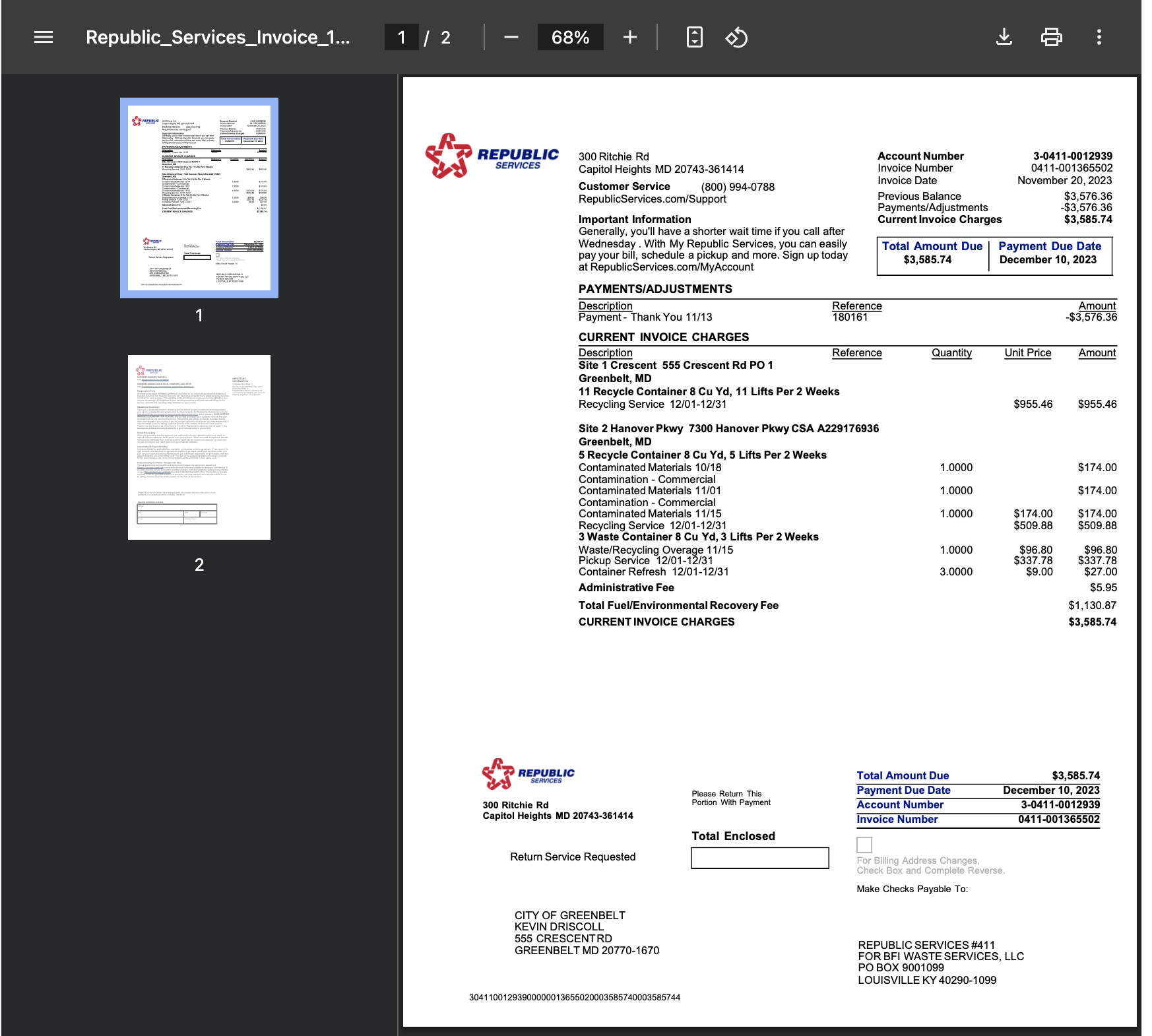 PDF to Excel Conversion Example
PDF to Excel Conversion Example
TL;DR
To extract data from PDF to Excel: (1) Upload your PDF to PDFScrape, (2) Define the data structure with our schema editor, (3) Run the extraction using our AI tools that can handle tables, forms, and even scanned documents, and (4) Download as Excel or CSV. For complex tables or recurring extractions, save your schema for future use.
Locked inside PDF files is valuable data that could be powering your spreadsheets, databases, and analytics. But PDFs were designed for consistent viewing, not for data extraction, making them notoriously difficult to work with when you need the underlying data.
Whether you're dealing with financial statements, research reports, invoice data, or survey results, manually copying data from PDFs is time-consuming, error-prone, and soul-crushing work. And traditional PDF converters often produce unusable results with misaligned columns, merged cells, and lost data relationships.
PDFScrape offers a smarter solution using AI-powered extraction tools that understand the structure of your documents, even when dealing with complex layouts, scanned pages, or inconsistent formatting.
Why Extract PDF Data to Excel?
Converting PDF data to Excel unlocks powerful capabilities that simply aren't possible while the data remains trapped in PDF format:
- Data Analysis: Apply formulas, functions, and calculations to reveal insights
- Visualization: Create charts, graphs, and dashboards to communicate findings
- Data Manipulation: Sort, filter, and reorganize information to find what matters
- Integration: Combine data from multiple PDFs or other sources for comprehensive analysis
- Automation: Feed data into other systems, reports, or automated workflows
- Collaboration: Share editable data with colleagues rather than static documents
Step-by-Step Guide to Extract PDF Data to Excel
Upload PDF
Upload any PDF document to the platform
Extract Text
PDFScrape extracts all text from the document
Chunk Text
Text is divided into manageable chunks for processing
Scrape Chunks
AI processes chunks using your schema
Recombine & Process
AI recombines and post-processes the data
Download CSV
Download your structured data as Excel/CSV
Step 1: Upload Your PDF Document
Start by uploading your PDF to PDFScrape from the dashboard. Click the "Upload Document" button or drag and drop your file.
Document Types Supported:
- Native PDFs - Digital PDFs with selectable text
- Scanned Documents - PDFs created from scanners or images
- Image-based PDFs - PDFs containing mostly images
- Password-protected PDFs - Secure documents (you'll need the password)
- Multi-page Documents - Extract from specific pages or the entire document
Pro Tip: For large files or bulk processing, consider using our batch upload feature that can handle up to 100 files simultaneously.
Step 2: PDFScrape Extracts Text
After uploading, PDFScrape automatically begins the text extraction process. This step includes:
- Character recognition - PDFScrape reads all text from the document
- Layout analysis - The system identifies the document structure
- OCR processing - For scanned or image-based documents
- Text normalization - Ensures consistent text formatting
This initial extraction captures all the text content from your PDF, regardless of format or complexity.
Step 3: Text is Divided into Chunks
To efficiently process large documents, PDFScrape divides the extracted text into manageable chunks. This chunking process:
- Maintains context - Ensures related text stays together
- Preserves document structure - Respects paragraph and section boundaries
- Optimizes for processing - Creates ideally-sized pieces for AI analysis
- Maintains sequence - Keeps track of each chunk's position in the document
Chunking allows the system to handle documents of any size while maintaining processing accuracy.
Get started instantly with PDFScrape
No credit card required. Free plan includes up to 50 pages per month.
Step 4: Create Schema and Scrape Chunks
This is where you define what data you want to extract from your PDF. Create a schema that tells PDFScrape exactly what to look for and how to structure it in your Excel output.
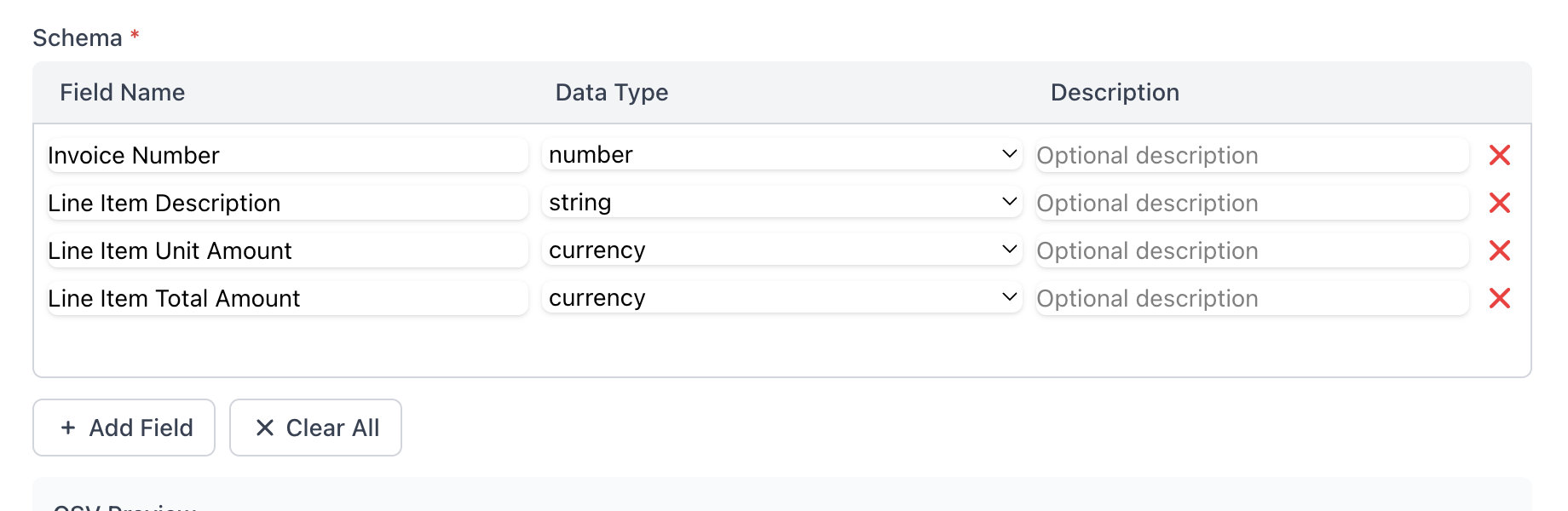 PDFScrape Schema Editor
PDFScrape Schema Editor
The schema editor allows you to:
- Define column headers - Name each column according to your Excel needs
- Specify data types - Ensure dates, numbers, and text are correctly formatted
- Set extraction parameters - Target specific tables, pages, or regions
- Create data relationships - Maintain hierarchy in complex datasets
- Add validation rules - Filter out unwanted data or ensure data quality
Schema Building Tips:
- For tables with headers, use the "Auto-detect Headers" feature
- For forms or invoices, use the "Key-Value Pair" extraction mode
- For complex tables, use the visual selector to define table boundaries
- For multi-page documents, specify whether to treat pages as separate tables or one continuous dataset
Once your schema is set up, PDFScrape's AI engine processes each chunk according to your specifications, extracting the exact data you need.
Step 5: Recombine Chunks and Post-Process
After processing individual chunks, PDFScrape intelligently recombines the results and applies advanced post-processing:
- Data consolidation - Merges data from related chunks
- Format standardization - Ensures consistent date, number, and text formats
- Duplicate removal - Eliminates redundant information
- AI-powered refinement - Applies advanced algorithms for data cleaning
- Structural validation - Ensures data maintains proper relationships
This step is critical for ensuring your final output is clean, consistent, and properly structured for analysis.
Common Extraction Challenges:
- Low-quality scans - Enhance document quality before upload or use our "Enhanced OCR" option
- Complex layouts - Use region selection to focus on specific areas of the document
- Merged cells - Enable "Handle Merged Cells" option in advanced settings
- Irregular tables - Use "Flexible Table Detection" for tables without clear boundaries
Step 6: Download Your Excel/CSV Data
The final step is to download your structured data. PDFScrape stores your processed data and makes it available in various formats:
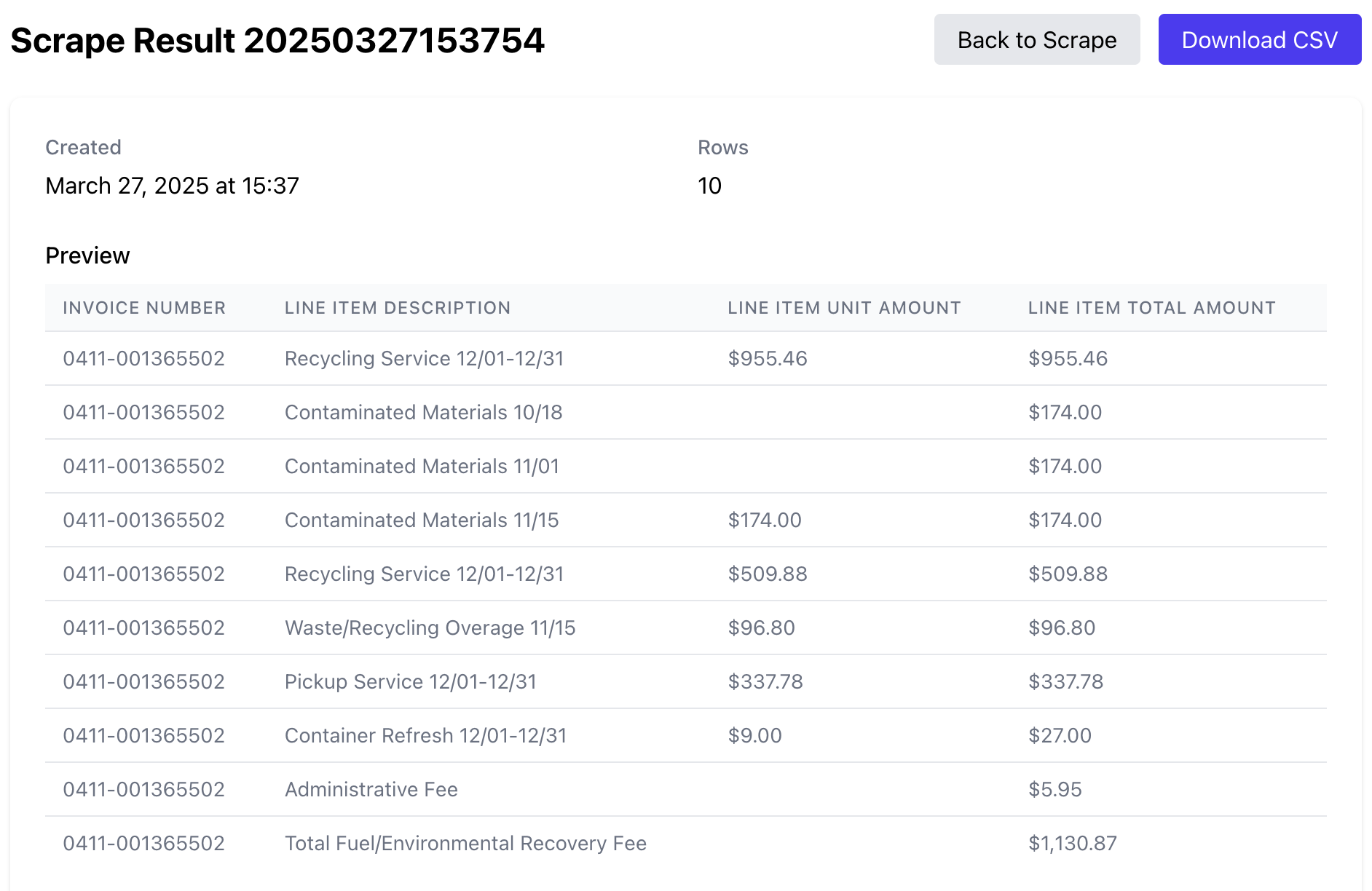 PDFScrape Data Preview & Export
PDFScrape Data Preview & Export
Before downloading, you can:
- Preview the extracted data to ensure accuracy and completeness
- Make final adjustments to the output if needed
- Choose your preferred format for download
Download options include:
- Excel (.xlsx) - Full Excel workbook with properly formatted cells
- CSV (.csv) - Simple comma-separated values for universal compatibility
- JSON (.json) - For developers or data integrations
- Custom API endpoint - For automated workflows (Enterprise plan)
Pro Tip: Save your extraction schema with a descriptive name if you'll need to extract similar PDFs in the future. This creates a reusable template that can save significant time.
Advanced Features for Complex PDF Data Extraction
Handling Multi-page Reports
Financial reports, research papers, and lengthy datasets often span multiple pages. PDFScrape offers specialized tools for these scenarios:
- Page Range Selection: Extract data from specific pages only
- Header/Footer Handling: Automatically remove repeating headers/footers
- Cross-page Table Detection: Properly connect tables that continue across page breaks
- Table of Contents Parsing: Jump directly to relevant sections in large documents
Data Cleanup and Transformation
Real-world PDFs rarely contain perfectly structured data. Our post-processing tools help you:
- Standardize Formats: Convert inconsistent date formats, numbers, and units
- Remove Unwanted Characters: Clean up extraction artifacts or special characters
- Split or Combine Columns: Restructure data to match your Excel requirements
- Apply Business Rules: Use conditional logic to transform or validate data
Batch Processing and Automation
For users with recurring extraction needs, PDFScrape offers powerful automation features:
- Scheduled Extractions: Set up weekly, monthly, or custom schedule jobs
- Email Notifications: Get alerted when extractions complete
- API Integration: Connect PDFScrape to your existing workflows
- FTP/Cloud Storage Integration: Automatically save results to your storage systems
- Extraction Templates: Reuse extraction settings across similar documents
Common PDF Extraction Challenges and Solutions
Challenge: Scanned Documents
Scanned PDFs contain images of text rather than actual text data.
Solution:
- Enable PDFScrape's "Advanced OCR" option
- Adjust contrast settings for better text recognition
- For poor quality scans, use "OCR Enhancement" setting
- Consider rescanning at 300 DPI if possible
Challenge: Complex Tables
Financial statements, research data, or statistical tables with merged cells or nested structures.
Solution:
- Use "Advanced Table Detection" mode
- Define table boundaries manually if needed
- Set "Hierarchical Data Structure" for nested tables
- Enable "Smart Cell Merging" for complex layouts
Challenge: Inconsistent Formatting
Documents with varying formats, fonts, or spacing that confuse standard extraction.
Solution:
- Use "Format-Adaptive Extraction" setting
- Create multiple extraction regions for different sections
- Apply custom regex patterns for specific data types
- Use post-processing rules to standardize extracted data
Challenge: Multi-column Layouts
Magazine-style PDFs with content flowing across multiple columns.
Solution:
- Enable "Multi-column Detection"
- Set reading order (left-to-right vs. top-to-bottom)
- Use column separators in the visual editor
- For complex layouts, extract columns separately
Real-World Use Cases
Financial Analysis and Reporting
Challenge: A financial analyst needed to extract quarterly financial data from 50+ PDF reports from different companies, each with their own formatting, to build a comparative analysis model.
Solution: Using PDFScrape's template system, they created extraction templates for each company's report style. The batch processing feature extracted all relevant financial metrics (revenue, expenses, profit margins, etc.) into a structured Excel workbook, saving approximately 40 hours of manual data entry while eliminating transcription errors.
Result: The analyst could now update their financial models within hours of new reports being published, giving their firm a competitive advantage in market analysis.
Academic Research Data Collection
Challenge: A research team needed to compile statistical data from 200+ academic papers for a meta-analysis study. Each paper contained tables with experimental results, but in inconsistent formats.
Solution: Using PDFScrape's flexible table detection and data standardization features, they created a schema that could identify key metrics across different paper formats. The system automatically normalized units and statistical notations into a consistent format.
Result: What would have been months of manual work was completed in days, allowing the research team to focus on analysis rather than data collection. The resulting dataset was more comprehensive than initially planned, strengthening the validity of their meta-analysis.
Invoice Processing Automation
Challenge: An accounting department was manually entering data from hundreds of vendor invoices each month, each with different formats, into their accounting system.
Solution: They implemented PDFScrape with multiple extraction templates for common vendor invoice formats. The system was configured to recognize invoice numbers, dates, line items, quantities, prices, and totals, then export this data in a format compatible with their accounting software.
Result: Processing time for invoices decreased from an average of 15 minutes per invoice to less than 1 minute. Data entry errors were virtually eliminated, and the accounting team could focus on higher-value tasks like financial analysis and vendor negotiation.
Transform Your Document Workflow
Join thousands of professionals who save hours every week by automating their PDF data extraction. Get started free today and see results in minutes.